How do Large Language Models (LLMs) work?
Large language models (LLMs) like ChatGPT, Bing’s new “Sydney” mode, and Google’s Bard are dominating the headlines.
Instead of discussing which jobs they’re going to make obsolete, this post will explore how these models function, including where they get their data and the basic math that enables them to generate convincingly realistic text.

Machine Learning 101
LLMs are a kind of Machine Learning model, just like many others. To grasp how they operate, let’s start by understanding the basics of Machine Learning in general.
Note: there are excellent visual resources online that explain Machine Learning in more detail and probably better than I can — I recommend checking them out! However, I’ll cover the fundamental concepts here.
The easiest way to grasp basic ML models is by thinking about prediction: based on what I already know, what’s likely to happen in a new situation? It’s similar to how your brain works.
Imagine you have a friend who’s always late. You’re planning a party, so you expect him to be late again. It’s not certain, but given his track record, you think there’s a good chance. If he arrives on time, you’re surprised, and you remember that for next time; maybe you’ll adjust your expectations about him being late.
Your brain has many of these models constantly working, but right now, we don’t fully understand how they actually work on the inside. In the real world, we have to make do with algorithms — some simple, some really complicated — that learn from data and make predictions about what might happen in new situations. Typically, models are trained to do specific things (like predicting stock prices or creating an image), but they’re starting to become more versatile.

A Machine Learning model is a bit like an API: it takes in inputs, and you teach it to produce certain outputs. Here’s the process:
1. Gather training data: Collect a bunch of data about what you want to model.
2. Analyze training data: Look at the data to find patterns and details.
3. Pick a model: Choose an algorithm (or a few) to understand the data and its workings.
4. Training: Run the algorithm, it learns, and stores what it figures out.
5. Inference: Present new data to the model, and it gives you its thoughts.
You create the model’s interface, deciding what information it receives and what it gives back, based on the specific job it needs to do.

What does the algorithm do, you ask? Well, think of it as a super-smart analyst. It discovers connections in the data you provide, connections that are often too tricky for you to spot on your own. The data usually has some X stuff — like features, settings, details — and some Y stuff — what actually went down. If you’re checking out this data:
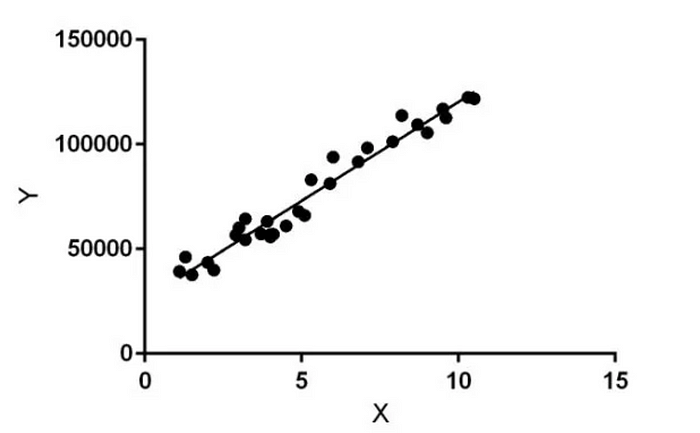
You don’t need ML to tell you that when X is 15, Y is around 150,000. But what if there are 30 different X things? Or the data looks all weird? Or it’s text? ML is all about tackling tricky situations where our human skills fall short. That’s it.
That’s why ML algorithms can be as basic as linear regression (like in Statistics 1) or as complex as a neural network with millions of nodes. The super-advanced models in the news lately are crazy complicated and took lots of people and years of research. But in many companies, Data Scientists use simple algorithms and still get good results.
🔍 Deeper Look 🔍
Building strong ML models from the ground up is a very specialized field. Some Data Scientists and ML Engineers create models using tools like PyTorch and Tensorflow, while others enhance existing open source models. You can also choose to have the whole model development process outsourced and use a ready-made one created by someone else.
🔍 Deeper Look 🔍
Creating a model is like a trial-and-error process. Unless your data is really straightforward, you’ll probably have to test different methods and make constant adjustments before your model starts making sense. It’s a mix of science, math, art, and a bit of randomness.
Language models and generating text
When your data has a time element — like predicting future stock prices or understanding an upcoming election — it’s pretty clear what a model is up to. It’s using the past to predict the future. However, many ML models, such as language models, don’t deal with time series data at all.
Language models are just ML models that handle text data. You train them on something called a “corpus” (or just a body) of text, and then you can use them for various tasks, like:
- Answering questions
- Searching
- Summarizing
- Transcription
The idea of language models has been around for a while, but the recent rise of deep learning with neural networks has been a big deal; we’ll talk about both.
Probabilistic Language Models
In simple terms, a probabilistic language model is like a probability map for words or groups of words. In English, it examines a chunk of text and analyzes which words show up, when they appear, how frequently, and the order they come in, and stuff like that. All this info is captured statistically.
Now, let’s quickly make our own language model.
Here are two sentences that might or might not express what I really think:
“The best Manhattan cocktail specification uses two ounces of Van Brunt Empire Rye, one ounce of Cocchi Di Torino Sweet Vermouth, one dash of Angostura Bitters, and one dash of Orange Bitters. I stir it in a mixing glass for about 60 turns, pour into a chilled Nick and Nora glass, and serve garnished with a Maraschino cherry.”
To make a simple probabilistic language model, we’ll collect n-grams, a fancy stats term for groups of words. Let’s set n=1, meaning we’ll just count how often words show up:
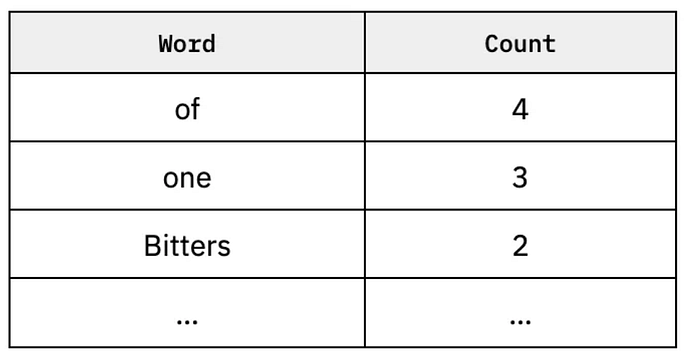
And if n=2:
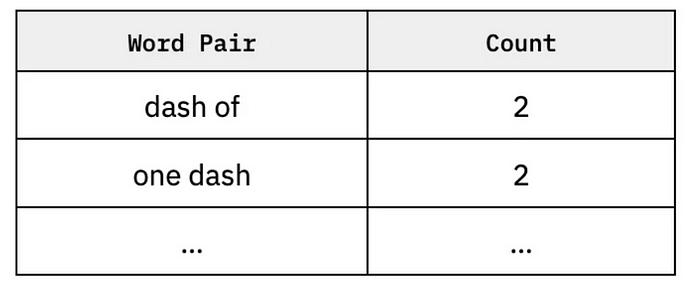
What the model does is make a bunch of n-grams, paying attention to which words show up together and in what order.
😰 Don’t sweat the details 😰
I go through the n-gram exercise just to show that what many models are doing isn’t really that complicated (though for some, it is). So, don’t stress if you didn’t get all of the details above.
😰 Don’t sweat the details 😰
Once you have that info stored, you predict which words might come next. If we were to create a new sentence from our two cocktail sentences, we’d put words together in a way that resembles the ones before.
Neural networks and language models
Probabilistic language models have been around for decades. Lately, though, it’s become more popular to use neural networks — a more complex algorithm — for language models. These networks learn what’s happening in a more meaningful way using something called embeddings. It’s tricky for models to learn directly from words, but much easier for them to learn from mathematical representations of those words.
Embeddings are a method of taking data with tons of dimensions — like giant bodies of text, with lots of discrete words and combinations — and mathematically representing them with less data, without losing much detail. Working with the text from 100 different 1,500-word blog posts about cocktail making (that’s 150K words!) is tough for an ML model. But if we can turn that information into a bunch of numbers, then we’re on the right track.
Equipped with a more user-friendly representation of words and text, neural networks can learn important things about text, like:
- Semantic relationships between words
- Bringing in more context (sentences before and after a word or sentence)
- Figuring out which words are important and which aren’t
This stuff gets pretty complex. But the goal is simple: a model powerful enough to consider a lot of context when predicting the next word, sentence, or paragraph, just like our brains do.
Large Language Models Now
ChatGPT and its cousins are essentially massive language models (that’s why they’re called that). They’re built on layers of advancements from the past decade, including:
- Word2Vec models
- LSTM (long short term memory) models
- RNN (recurrent neural networks)
- Transformers (yes) (also known as “foundation models”)
You don’t really have to know what each of these is. The key is to realize that these big language models aren’t some sudden scientific breakthrough. Researchers have been steadily progressing towards today’s reality for years, and each new development played a crucial role in reaching this point. There was a big hype cycle when LSTMs gained traction in 2019 (even though the concept was introduced in the 90s), and the same goes for all these. Research is a bit weird!
The way ChatGPT and LLMs create whole paragraphs of text is by playing a word guessing game, over and over.
Here’s the rundown:
1. You give the model a prompt (this is the “predict” phrase).
2. It predicts a word based on the prompt.
3. It predicts a second word based on the first word.
4. It predicts a third word based on the first two words.
5. …
It’s pretty basic when you break it down. But it turns out the word guessing game can be super powerful when your model is trained on all the text on the entire internet. Data Scientists often say about ML models, “garbage in means garbage out” — meaning your models are only as good as the data you use to train them. With OpenAI partnering with Microsoft, they’ve been able to use a ton of computing resources to gather this data and train these models on powerful servers.
With the entire written internet as context, LLMs can produce sentences that rarely deviate from something “normal,” unlike older models. If the phrase “I Angostura my cocktail with Manhattan ice around glass twist” doesn’t exist anywhere on the web, the model probably won’t generate it. And this simple truth is a big reason why these models are so good.

This raises a key question: Do these LLMs really grasp the answers they provide? Figuring this out involves a mix of math, philosophy, and semantics (what does “understand” really mean?).
